Kubernetes集群架构
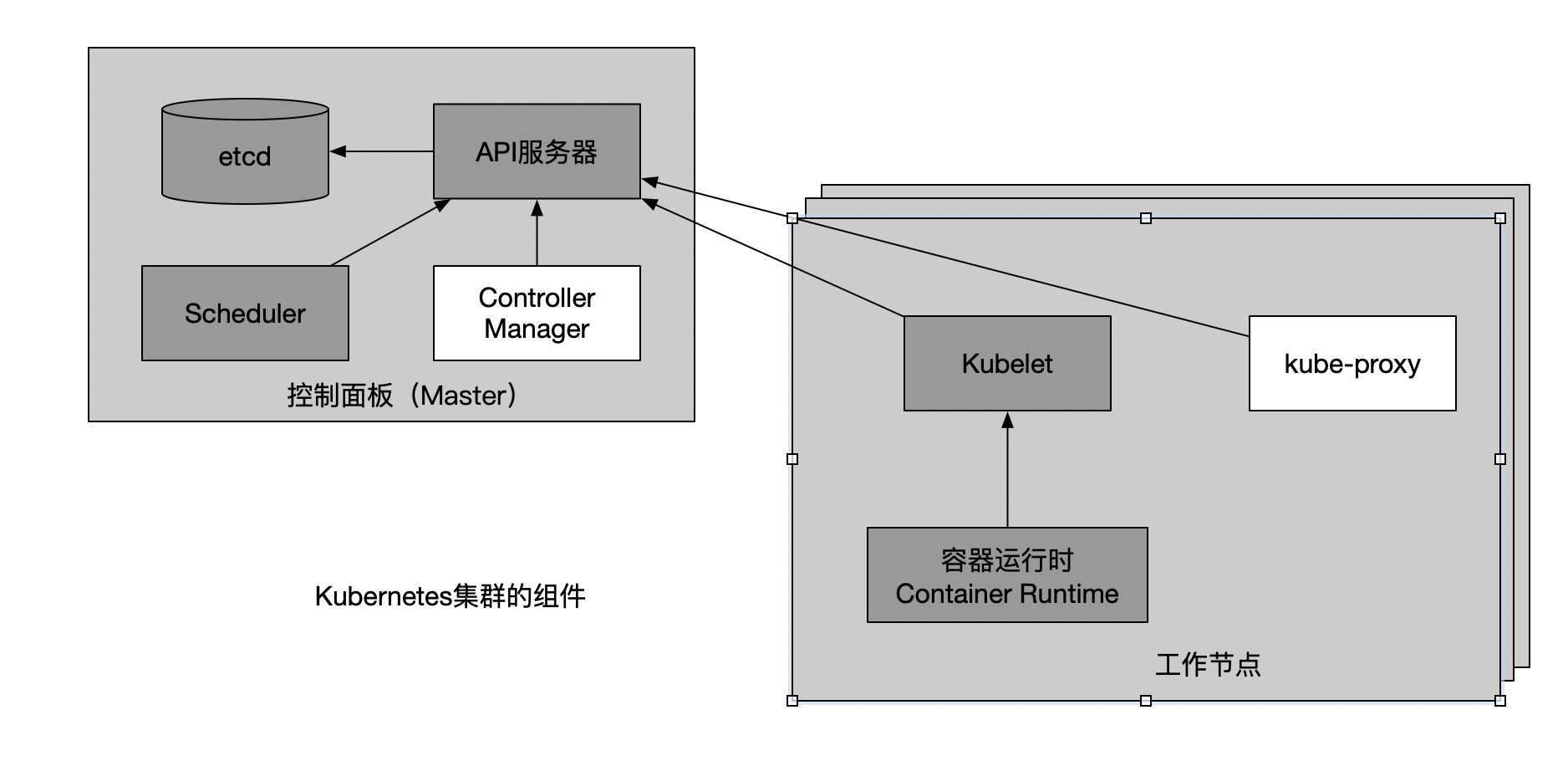
控制面板
包含多个组件,组件分别部署在多个主节点保证高可用:
- Kubernetes API服务器
- Scheduler
- Controller Manager 执行集群级别的任务,如复制组件、持续跟踪工作节点、处理节点失败等
- etcd 持久化存储集群配置
工作节点
运行容器化应用的机器,也包含多个组件:
- Docker、rtk或其他的容器类型
- Kubelet,他与API服务器通信,管理他所在节点的容器
- Kubernetes Service Proxy(kube-proxy)负责组件之间的负载均衡网络流量
Kubernetes 强大的标签
kubernetes标签选择器
1 | # 根据标签值筛选 |
1 | # 列出包含某标签的pod |
1 | # 列出不存在某标签 |
1 | # 列出值匹配的 |
1 | # 多条件 |
利用标签约束pod调度
1 | # 1. 利用标签分类工作节点 |
1 | # 2. 将pod调度到gpu节点 |
Kubernetes探针
存活探针liveness probe
- HTTP Get 探针。返回码为2xx或3xx,则认为成功,否则容器将被重新启动
- TCP套接字探针。尝试与容器指定端口建立套接字链接
- Exec探针。在容器内执行任意命令并检查命令的退出命令码,正常退出码为0
1 | apiVersion: v1 |
就绪探针readinessProbe
和存活探针一样的类型种类
Kubernetes ReplicationController
- 好处
- 确保一个或多个pod副本持续运行,pod故障后会自动启动一个新的pod
- 节点故障后也会在其他节点创建替代副本:节点故障时节点状态变为NotReady。k8s会等待一段时间,然后将pod状态变成Unknown,然后立即启动一个新的pod
- 轻松实现pod的水平伸缩
- 定义
1 | apiVersion: v1 |
针对修改—关于标签和模板
删除ReplicationController时会连带删除掉它所管理的所有pod
1
2# 可以通过增加cascade保持pod运行
kubectl delete rc kubia --cascade=falseReplicationController运行后新增pod标签不会影响ReplicationController的副本数目
删除或修改pod的selector标签,该pod将被移出ReplicationController的管理,ReplicationController会新建一个pod保证副本数
修改ReplicationController的模板不会对当前pod造成影响,只会影响之后新建的pod
伸缩
1 | kubectl scale rc kubia --replicas=5 |
Kubernetes ReplicaSet
ReplicationController的替代。
行为与ReplicationController一致,但是pod选择器的表达能力更强。比如ReplicaSet可以同时匹配多组标签,而且可以基于标签名的存在性来匹配。
定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: kubia
spec:
replicas: 3
selector:
matchLabels: #多个标签的匹配,也可以是
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia增强型标签选择器
1
2
3
4
5
6
7selector:
matchExpressions:
- key: app # 标签名字
#In NotIn Exists(包含,不指定values) DoesNotExist(不得包含,不指定values)
operator: In
values:
- kubia
Kubernetes DaemonSet
在匹配某标签的每个节点上,启动一个Daemon pod。
1 | apiVersion: apps/v1 |
如果节点的标签从ssd修改为hdd,则对应的pod也会跟着终止掉。
Kubernetes Job
Job的内部进程成功结束后,不重启容器,处于完成状态。如果进程异常退出,可以将Job配置为重新启动。
1 | apiVersion: batch/v1 |
Job可以创建多个pod实例,一并行或串行方式运行。通过配置completions和parallelism属性。
1 | apiVersion: batch/v1 |
运行逻辑:第一个pod运行完成,继续创建第二个,相当于相同的逻辑起5次pod来执行。
当parallelism>1时,表示可以同时有parallelism个pod同时运行。
CronJob
1 | apiVersion: batch/v1 |
Kubernetes Service — 集群内部服务
1 | apiVersion: v1 |
1 | ➜ k8s-in-action kubectl get po |
– 双横杠表示kubectl命令的结束。横杠之后的内容指需要在pod内部执行的命令。如果后面的命令不带横杠参数,如不带-s,则双横杠不是必须的。
Kubernetes Endpoints — 使用集群外部服务
集群内部服务也有endpoints,通过命令 kubectl describe svc kubia 可以看到。
1 | ➜ k8s-in-action kubectl describe svc kubia |
手工配置的endpoints主要用来配置集群外部服务。
步骤如下:
创建没有选择器的服务S
1
2
3
4
5
6
7apiVersion: v1
kind: Service
metadata:
name: external-service
spec:
ports:
- port: 80为服务S创建
Endpoints资源1
2
3
4
5
6
7
8
9
10apiVersion: v1
kind: Endpoints
metadata:
name: external-service # 名称必须和服务名称相匹配
subsets:
- addressses:
- ip: 11.11.11.11
- ip: 22.22.22.22 # endpoint的ip地址
ports:
- port: 80 # endpoint的目标端口
暴露服务
NodePort方式
1
2
3
4
5
6
7
8
9
10
11
12apiVersion: v1
kind: Service
metadata:
name: kubia-nodeport
spec:
type: NodePort
ports:
- port: 80 # 暴露出去的端口
targetPort: 8080 # 容器内部的服务端口,这里也可使用pod里ports的名字代替
nodePort: 30123 # 如果不指定,将随机分配一个端口
selector:
app: kubia # 标签为kubia的pod都属于这个服务1
2
3
4
5
6➜ k8s-in-action kubectl apply -f kubia-svc-nodeport.yaml
service/kubia-nodeport created
➜ k8s-in-action kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 11h
kubia-nodeport NodePort 10.104.247.31 <none> 80:30123/TCP 4s接下来,可以通过10.104.247.31:80,
:30123, :30123去访问服务了。 minikube用户可以直接通过以下命令快速查看nodeport服务:
1
2
3
4
5
6
7➜ k8s-in-action minikube service kubia-nodeport
|-----------|----------------|-------------|---------------------------|
| NAMESPACE | NAME | TARGET PORT | URL |
|-----------|----------------|-------------|---------------------------|
| default | kubia-nodeport | | http://192.168.64.2:30123 |
|-----------|----------------|-------------|---------------------------|
🎉 Opening service default/kubia-nodeport in default browser...LoadBalance方式
注:minikube当前还不支持
1
2
3
4
5
6
7
8
9
10
11apiVersion: v1
kind: Service
metadata:
name: kubia-loadbalancer
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 8080
selector:
app: kubia创建Ingress资源
每个LoadBalancer都需要自己的负载均衡器以及独有的公有的IP地址,而Ingress只需要一个公网IP就能为许多服务提供访问。还可以提供基于Cookie的会话亲和性(session affinity)。
1
2
3
4
5
6
7
8
9
10
11
12
13apiVersion: v1
kind: Ingress
metadata:
name: kubia
spec:
rules:
- host: kubia.example.com #将域名映射到服务
http:
paths:
- path: /
backend:
serviceName: kubia-nodeport #将所有请求发给nodeport服务的80端口
servicePort: 80测试:
启动nodeport和rs
解析hosts
1
$ echo "$(minikube ip) kubia.example.com" | sudo tee -a /etc/hosts
minikube必备:
1 | # 开启ingress |
