索引生成
索引与索引直接并无直接关联,他们是相互独立的。
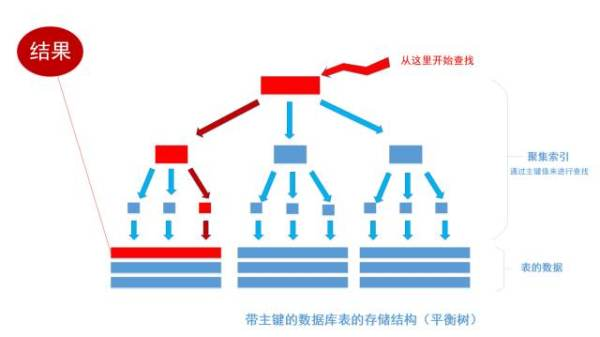
聚集索引
当我们给一个数据库表分配一个主键时,这时就会生成一棵平衡树结构。这个即该表的索引树。也就是说,数据库表生来就是一颗带有数据的索引树,数据均存储在叶子节点。多达10+的分叉树结构,把大数据量搜索所需的查询次数指数级的减少,极大地降低了io消耗,从而提高性能。
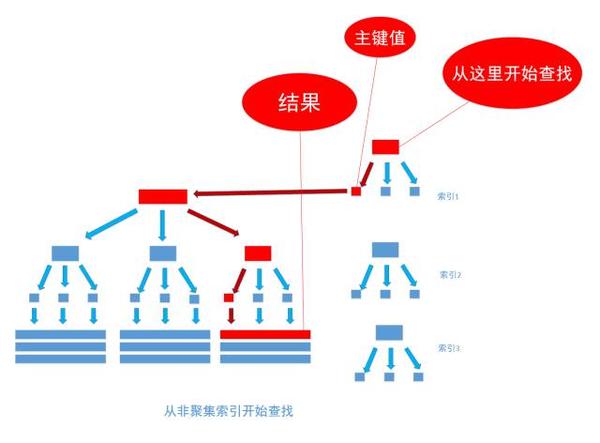
非聚集索引
当我们给数据库表增加普通索引、唯一索引时,这时数据库会从源表数据复制出相应的列数据出来,然后构造成一颗多叉树。同样,当匹配条件与该索引树匹配时,会迅速在叶子节点找到相应的数据。
不一样的是,这里找到的是数据的聚集索引,然后数据库根据簇集索引找到对应的数据。所以,非聚集索引的查询最终还是会检索一遍聚集索引。
覆盖索引
查询条件和返回结果直接覆盖在所查索引树内时,这样的索引叫覆盖索引。他的表现为复合索引,只不过他不需要进行回表扫描,所有的数据就在索引树内。
1
2
3
4
5
6
7
8
9
10
11
12
13mysql> explain select name from user where birthday > '2000-01-01'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user
type: range
possible_keys: idx_birth
key: idx_birth
key_len: 3
ref: NULL
rows: 15734
Extra: Using index condition
1 row in set (0.00 sec)Extra 为 Using index condition 说明使用的检索方式为二级检索,即7999个书签值被用来进行回表查询。
这句sql里查询用到2个字段,创建birthday和name的复合索引,然后再查询。
1
2
3
4
5
6
7
8
9
10
11
12
13mysql> explain select name from user where birthday > '2000-01-01' \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user
type: range
possible_keys: idx_birth_name, idx_birth
key: idx_birth_name
key_len: 3
ref: NULL
rows: 1684
Extra: Using index
1 row in set (0.00 sec)Extra提示信息为Using index而不是Using index condition,代表没有了回表查询的过程,也就是实现了索引覆盖。
